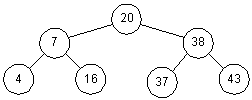
Figure 3-2: A Binary Search Tree

B-Tree algorithm:
Recursive
Insert value in tree
Insert value in subtree starting at root node
if root node split,
Create new root node with middle value, left child points to left
split node and child after middle value is right split node.
Insert value into subtree starting at node T:
if T is a leaf node,
Insert value into node T (no children)
else
if value < first key in T then
Insert value into subtree starting at left child
else
Find first key such that value < key
Insert value into subtree starting at child immediately after key
if child node split,
Insert its middle value into node T after key
(Key's pointer points to left split node
Middle value's pointer points to right split node)
Insert value into node T:
if node T is full,
split into left node < middle value
and right node > middle value
if value < middle value,
Insert value into left node
else
Insert value into right node.
Delete value from tree:
Search root of tree for first key >= value
if key = value then
if root is a leaf then
Remove key from root
else
if left child of key is fuller than right child then
Delete Immediate Predecessor of key
else
Delete Immediate Successor of key
Replace key with deleted key from previous operation
If child node is < 1/2 full then
if neighbor is > 1/2 full then
rotate first or last key of neighbor (depending on
direction of move) into root to replace key between
the child and the neighboring sibling and move that key
into the child node
else
join child with neighboring sibling
Remove key between them from root
Insert key between them into node resulting from the join
if number of keys in root = 0, replace root with only
remaining child.
else
Delete value from subtree before key
(or right subtree if no keys are > value)
if subtree < 1/2 full then
... same procedure as above
Delete immediate predecessor of key:
Delete rightmost value of left child (before) key, returning that value
if left child < 1/2 full then
... same as above
Delete rightmost value of tree:
if tree root is not leaf (subtree is taller than one level), then
Delete rightmost value of right child of root (pointer after last key)
if right child of root < 1/2 full then
... same as above
else
Remember rightmost key and delete it from "root" of subtree.
btree.cpp